What is Serverless Computing in AWS and how does it work?
What is Serverless Computing in AWS and how does it work?
Serverless Computing in AWS
The term serverless computing gained fame as Amazon initially started AWS Lambda in 2014. From that point on the traditional server-based computing was set aside to welcome this new, clean, and hassle-free service by AWS. The traditional server-based computing follows a three-tier architecture — with database layer, application layer, and presentation layer. In the traditional method, the developer has to focus on first setting up and configuring servers, install the necessary software, manage them on an ongoing basis, take care of hardware and software of grades, work on the availability, scalability, and tolerance of the application. All this comes with added resources, infrastructure, and cost.
Serverless computing changes this paradigm altogether. All these steps, apart from writing the application code are no longer needed. Serverless applications allow you to focus on your application lodging without having to agonize over the creation and maintenance of servers. The ease of serverless computing is that there are no servers to maintain, no operating systems to take care of, no software and hardware to upgrade and your applications have in-built high availability and fault tolerance.
How does it work?
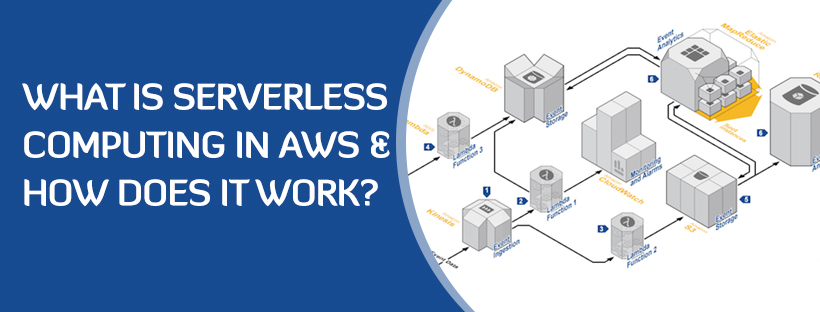
Serverless Computing in AWS is an orchestration of different AWS products. Fundamentally, the serverless design comprises of uses that commonly rely upon Backend-as-a-Service (BaaS) and Function-as-a-Service (FaaS). Consolidating the capacities of these two models enables the cloud framework of the firm’s environment. While BaaS enables the engineers to focus on the customer activities without thinking about the backend assets, FaaS gives a confirmation layer through an API when the customers get to the database. AWS Lambda is reigning the world of cloud computing today and here is how it functions in relation to S3.
The user transfers some data/ object to a bucket in S3, which has notification connected to it, for Lambda.
The notification is sent to Lambda by S3.
Execution job in Lambda can be characterized by utilizing IAM (Identity and Access Management) to authorize for the AWS assets to be utilized, for this model here it would be S3.
At last, it turns on the Lambda function which is functioning on that specific object in the S3 bucket.
So who can work with Lambda?
At present, AWS Lambda is supporting different languages such as Python, Java, C#, Go, and Node.js. This maximizes the runtime as Lambda allows much flexibility in requests. At the same time, the coder can figure out other things at the backend. The database is in the virtual world, making the execution capacity more efficient and risk-proof. The infrastructure is distributed dynamically to the allocated resources (the billing is done only for used resources).
There are several services and products by AWS that work together to complete the process of serverless computing namely S3, EC2, Lambda, Beanstalk, IAM, API Gateway, SQS, SNS, Greengrass, Glacier, and many others with four major benefits:
- No servers to create, provision or maintain
- Never pay for idle lying resources
- Auto scales itself with usage, and
- Comes with in-built fault tolerance
Serverless Computing in AWS takes off the burden of the developer and leaves him/her to just code the application.